检测python爬虫时是否代理ip伪装成功的方法
有时候我们的爬虫程序添加了代理,但是我们不知道程序是否获取到了ip,尤其是动态转发模式的,这时候就需要进行检测了,以下是一种代理是否伪装成功的检测方式,这里推介使用亿牛云提供的代码示例。
Python¶
requests
#! -*- encoding:utf-8 -*-
import requests
import random
# 要访问的目标页面
targetUrl = "http://httpbin.org/ip"
# 要访问的目标HTTPS页面
# targetUrl = "https://httpbin.org/ip"
# 代理服务器
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理隧道验证信息
proxyUser = "16ZKBRLB"
proxyPass = "234076"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {"Proxy-Tunnel": str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text
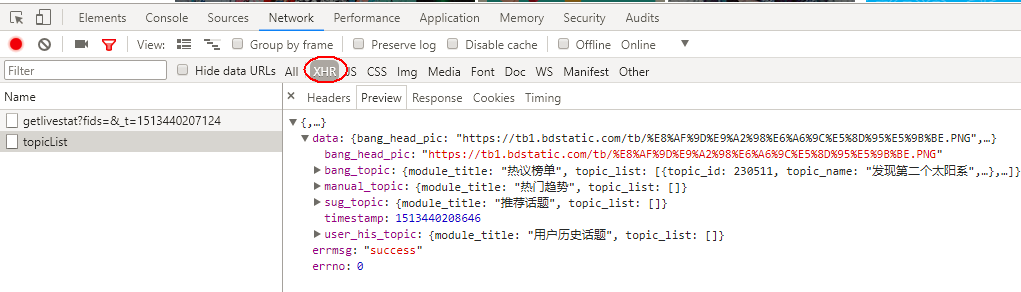
要检测代理是否获取到,直接在配置代理后访http://httpbin.org/ip网站,获取到ip后再访问www.ip138.com就知道是否获取到了ip。