Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目
scrapy startproject zhaoping
创建爬虫
cd zhaoping scrapy genspider hr zhaopingwang.com
目录结构
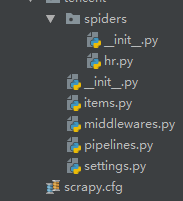
items.py
title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field()
pipelines.py
from pymongo import MongoClient
mongoclient = MongoClient(host='192.168.226.150',port=27017)
collection = mongoclient['zhaoping']['hr']
class TencentPipeline(object):
def process_item(self, item, spider):
print(item)
# 需要转换为 dict
collection.insert(dict(item))
return item
spiders/hr.py
def parse(self, response):
# 不要第一个 和最后一个
tr_list = response.xpath("//table[@class='tablelist']/tr")[1:-1]
for tr in tr_list:
item = TencentItem()
# xpath 从1 开始数起
item["title"] = tr.xpath("./td[1]/a/text()").extract_first()
item["position"] = tr.xpath("./td[2]/text()").extract_first()
item["publish_date"] = tr.xpath("./td[5]/text()").extract_first()
yield item
next_url = response.xpath("//a[@id='next']/@href").extract_first()
# 构造url
if next_url != "javascript:;":
print(next_url)
next_url = "https://hr.tencent.com/" + next_url
yield scrapy.Request(url=next_url,callback=self.parse,)
就是这么简单,就获取到数据
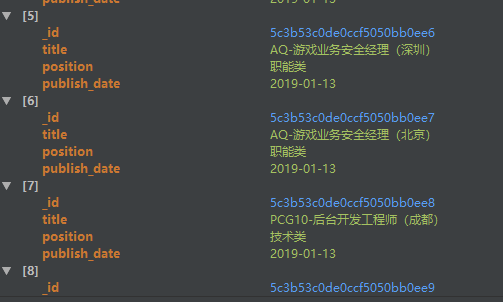
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。