用python3 urllib破解有道翻译反爬虫机制详解
前言
最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果。发现接口变化很大,用md5加了密,于是自己开始破解。加上网上的其他文章找源码方式并不是通用的,所有重新写一篇记录下。
爬取条件
要实现爬取的目标,首先要知道它的地址,请求参数,请求头,响应结果。
进行抓包分析
打开有道翻译的链接:http://fanyi.youdao.com/。然后在按f12 点击Network项。这时候就来到了网络监听窗口,在这个页面中发送的所有网络请求,都会在Network这个地方显示出来,如果是空白的,点击XHR。接着我们在翻译的窗口输入我们需要翻译的文字,比如输入hell。然后点击自动翻译按钮,那么接下来在下面就可以看到浏览器给有道发送的请求,这里截个图看看:
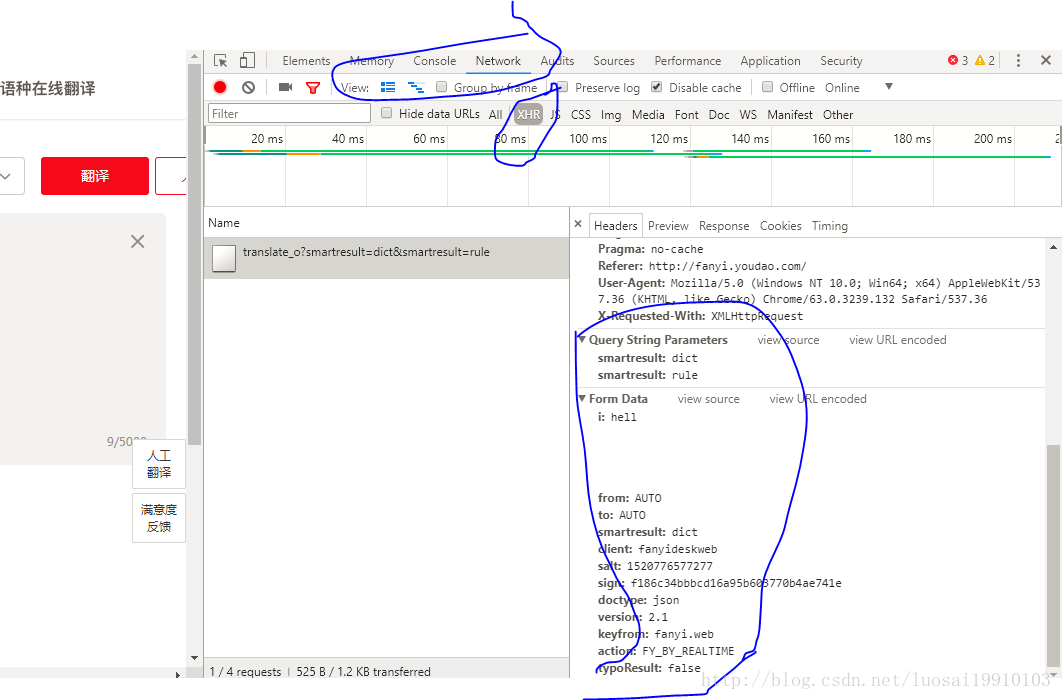
点击链接,就可以看到整个请求的信息。包括请求头,请求参数,响应结果。
这里面有一个问题就是参数进行了加密。我们需要知道这些参数是如何加密的。
破解加密难题
要想知道如何加密的,需要查看源码。于是我们需要知道发起这个请求的js文件。在文件查找这个相关代码。刚才我们监听了网络请求,可以看到发起请求的js文件。那么接下来查找发起请求的链路,鼠标浮到请求文件上,显示了一系列执行方法,我们点击跟业务相关的那个方法对应的文件链接,这里是t.translate 对应的连接。

点击进入查看对应的源码
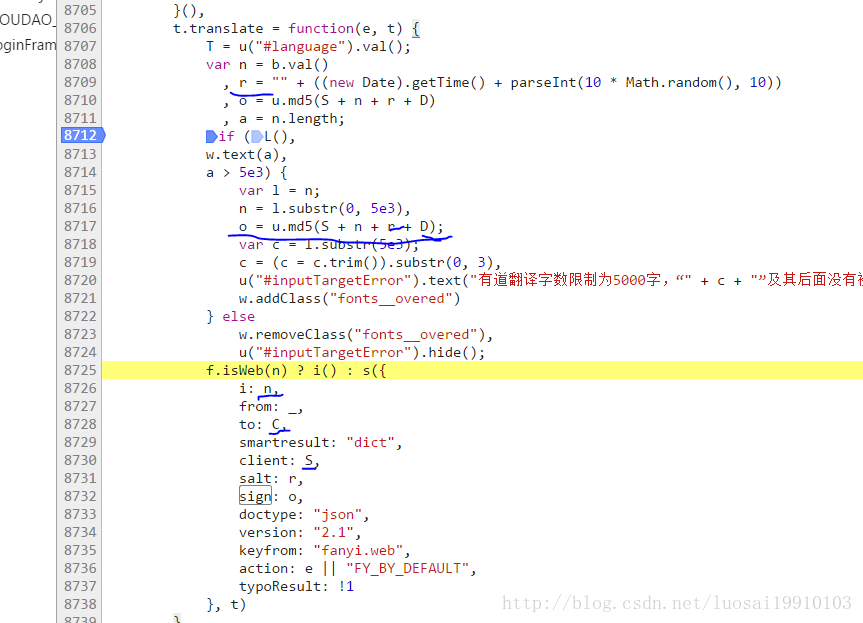
我们可以看到i,salt,sign是变量,其他的请求参数是常量。i是需要翻译的字符串,salt是时间戳生成的13位,sign是S+n+r+D
也就S是client的值,也就是fanyideskweb. 我们查找D 这个常量,在底栏输入框输入 D = (空格D空格=空格;格式化后的代码规范)点击右边的Aa让搜索时大小写敏感。回车查找到下一个,直到找到对应的值。
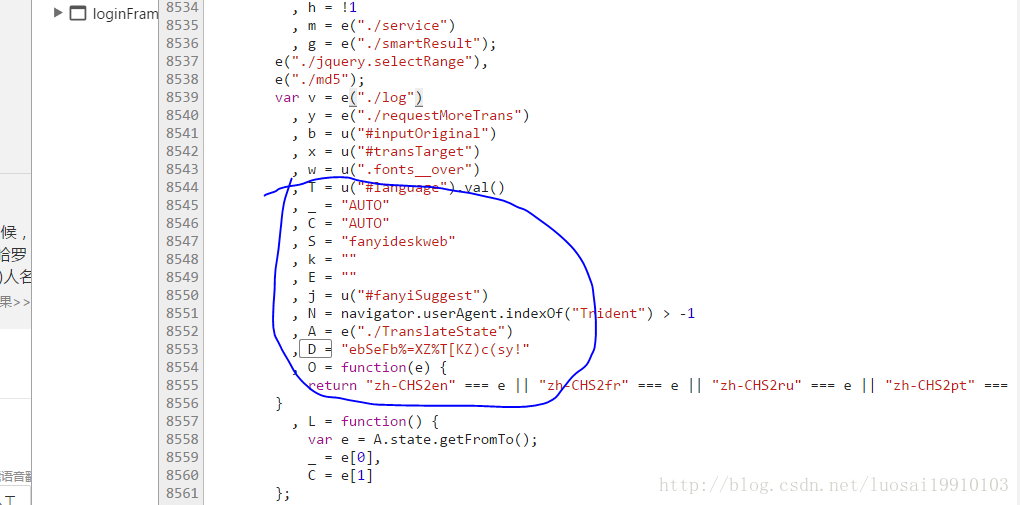
在上图我们看到了_,C,S,D等常量。
于是你以为构建一个请求,传好这些参数就ok了。别忘了,为了反爬虫,都是会校验请求头。于是要模拟浏览器的请求头。经过验证只需要User-Agent,Referer,Cookie 三个请求头。
实现代码:
# -*- coding: utf-8 -*-
from urllib import request,parse
import json
import time
from hashlib import md5
'''
def dicToSortedStrParam(dic={}):
keyList = sorted(dic)
str =""
for i,key in enumerate(keyList):
if i==len(keyList)-1:
str += key +"="+ dic[key]
else:
str += key +"="+ dic[key] + "&"
pass
return str
'''
def create_md5(data):
md5_obj = md5()
md5_obj.update(data.encode("utf-8"))
return md5_obj.hexdigest()
if __name__ == "__main__":
request_url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
translate = "hell"
c = "fanyideskweb"
data = {}
data["i"] = translate
data["from"] = "AUTO"
data["to"] = "AUTO"
data["smartresult"] = "dict"
data["client"] = c
data["doctype"] = "json"
data["version"] = "2.1"
data["keyfrom"] = "fanyi.web"
data["action"] = "FY_BY_REALTIME"
data["typoResult"] = "false"
salt = str(int(round(time.time(),3)*1000))
# 加密
data["salt"] = salt
# a = "rY0D^0'nM0}g5Mm1z%1G4" 网上别人的 也可以
a = "ebSeFb%=XZ%T[KZ)c(sy!"
sign = create_md5(c+translate+salt+a)
data["sign"] = sign
headers = {}
headers["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
# headers["Content-Type"] = "application/x-www-form-urlencoded; charset=UTF-8"
headers["Referer"] = "http://fanyi.youdao.com/"
# headers["Host"] = "fanyi.youdao.com"
# headers["Origin"]="http://fanyi.youdao.com"
headers["Cookie"]="OUTFOX_SEARCH_USER_ID=-948455480@10.169.0.83; " \
"JSESSIONID=aaajvZPcjhFWbgtIBPuiw; " \
"OUTFOX_SEARCH_USER_ID_NCOO=1148682548.6241577;" \
" fanyi-ad-id=41685; fanyi-ad-closed=1; ___rl__test__cookies="+salt
data = parse.urlencode(data).encode('utf-8')
request1 = request.Request(request_url,data,headers = headers)
response = request.urlopen(request1)
print(response.info())
#读取信息并解码
html = response.read().decode('utf-8')
print(html)
#使用JSON
translate_results = json.loads(html)
# 找到翻译结果
translate_results = translate_results['translateResult'][0][0]['tgt']
# 打印翻译信息
print("翻译的结果是:%s" % translate_results)
翻译结果:
{"translateResult":[[{"tgt":"地狱","src":"hell"}]],"errorCode":0,"type":"en2zh-CHS","smartResult":{"entries":["","n. 地狱;究竟(作加强语气词);训斥;黑暗势力\r\n","vi. 过放荡生活;飞驰\r\n","int. 该死;见鬼(表示惊奇、烦恼、厌恶、恼怒、失望等)\r\n"],"type":1}}
翻译的结果是:地狱
翻译的结果是:地狱
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。