关于pytorch多GPU训练实例与性能对比分析
以下实验是我在百度公司实习的时候做的,记录下来留个小经验。
多GPU训练
cifar10_97.23 使用 run.sh 文件开始训练
cifar10_97.50 使用 run.4GPU.sh 开始训练
在集群中改变GPU调用个数修改 run.sh 文件
nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU &
修改 –gres=gpu:2 即可
Python 文件代码修改
parser.add_argument('--batch_size', type=int, default=96*2, help='batch size')
修改对应 batch size 大小,保证每块GPU获得等量的训练数据,因为batch_size的改变会影响训练精度
最容易实现的单GPU训练改为多GPU训练代码
单GPU:logits, logits_aux = model(input)
多GPU:
if torch.cuda.device_count()>1:#判断是否能够有大于一的GPU资源可以调用 logits, logits_aux =nn.parallel.data_parallel(model,input) else: logits, logits_aux = model(input)
缺点:不是性能最好的实现方式
优点:代码嵌入适应性强,不容易报错
性能分析
该图为1到8GPU训练cifar10——97.23网络的实验对比
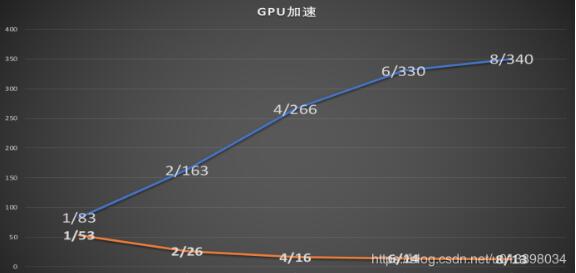
可以看到单核训练600轮需要53小时、双核训练600轮需要26小时、四核16、六核14、八核13。
在可运行7小时的GPU上的对比实验:单核跑完83轮、双核跑完163轮、四核跑完266轮
结论:性价比较高的是使用4~6核GPU进行训练,但是多GPU训练对于单GPU训练有所差异,训练的准确率提升会有所波动,目前发现的是负面的影响。
以上这篇关于pytorch多GPU训练实例与性能对比分析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。