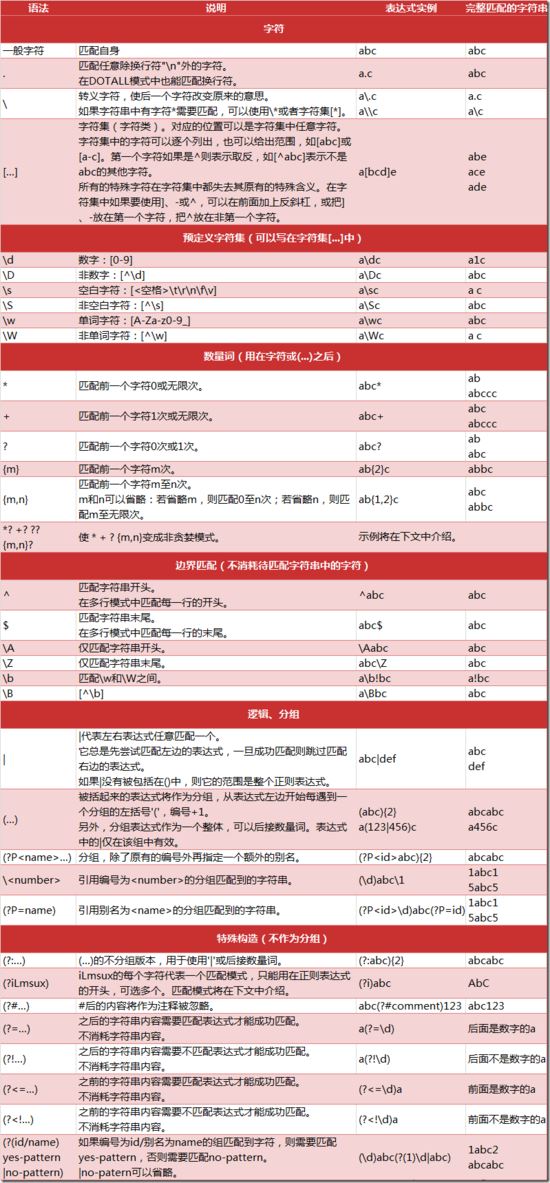
python爬虫中多线程的使用详解
queue介绍
queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue。python3直接queue即可
在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性。
#多线程实战栗子(糗百)
#用一个队列Queue对象,
#先产生所有url,put进队列;
#开启多线程,把queue队列作为参数传入
#主函数中读取url
import requests
from queue import Queue
import re,os,threading,time
# 构造所有ip地址并添加进queue队列
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
urlQueue = Queue()
[urlQueue.put('http://www.qiumeimei.com/image/page/{}'.format(i)) for i in range(1,14)]
def get_image(urlQueue):
while True:
try:
# 不阻塞的读取队列数据
url = urlQueue.get_nowait()
# i = urlQueue.qsize()
except Exception as e:
break
print('Current Thread Name %s, Url: %s ' % (threading.currentThread().name, url))
try:
res = requests.get(url, headers=headers)
url_infos = re.findall('data-lazy-src="(.*?)"', res.text, re.S)
for url_info in url_infos:
if os.path.exists(img_path + url_info[-20:]):
print('图片已存在')
else:
image = requests.get(url_info, headers=headers)
with open(img_path + url_info[-20:], 'wb') as fp:
time.sleep(1)
fp.write(image.content)
print('正在下载:' + url_info)
except Exception as e:
print(e)
if __name__ == '__main__':
startTime = time.time()
# 定义图片存储路径
img_path = './img/'
if not os.path.exists(img_path):
os.mkdir(img_path)
threads = []
# 可以调节线程数, 进而控制抓取速度
threadNum = 4
for i in range(0, threadNum):
t = threading.Thread(target=get_image, args=(urlQueue,))
threads.append(t)
for t in threads:
t.start()
for t in threads:
# 多线程多join的情况下,依次执行各线程的join方法, 这样可以确保主线程最后退出, 且各个线程间没有阻塞
t.join()
endTime = time.time()
print('Done, Time cost: %s ' % (endTime - startTime))
总结
以上所述是小编给大家介绍的python爬虫中多线程的使用详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!