Python箱型图绘制与特征值获取过程解析
这篇文章主要介绍了Python箱型图绘制与特征值获取过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较
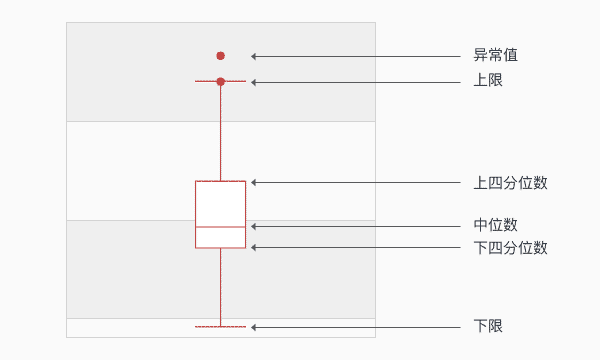
如何利用Python绘制箱型图
需要的import的包
import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties import numpy as np import pandas as pd
该函数是绘制多箱型图,且数据长度不一致的情况,input_dict = {filename1:[a1,a2,...,an],filename2:[b1,b2,...,bn]...} Y_label = 'Img_name'
def DrawMultBoxPic(input_dict,Y_label):
dict_list_length = []
for item in input_dict:
temp_length = len(input_dict[item])
dict_list_length.append(temp_length)
# 获取最长列表长度
max_length = max(dict_list_length)
# 每个列表在后面追加None
for item in input_dict:
diff_length = max_length - len(input_dict[item])
if diff_length > 0:
for i in range(diff_length):
input_dict[item].append(None)
# else:
# print('{}文件列表长度最长'.format(item))
# 绘制箱型图
zhfont = FontProperties(fname='C:/Windows/Fonts/simsun.ttc', size=16)
data = pd.DataFrame.from_dict(input_dict)
data.boxplot(widths=0.3,figsize=(30,15),fontsize=16)
plt.xlabel(u'煤质文件名称', fontproperties=zhfont)
plt.ylabel(Y_label, fontproperties=zhfont)
plt.title(Y_label, fontproperties=zhfont)
# plt.axis([0, 6, 0, 90])
plt.grid(axis='y', ls='--', lw=2, color='gray', alpha=0.4)
plt.grid(axis='x', ls='--', lw=2, color='gray', alpha=0.4)
imgname = 'E:\\' + Y_label + '.png'
plt.savefig(imgname, bbox_inches = 'tight')
# plt.show()
结果显示
如何获取箱型图特征
"""
【函数说明】获取箱体图特征
【输入】 input_list 输入数据列表
【输出】 out_list:列表的特征[下限,Q1,Q2,Q3,上限] 和 Error_Point_num:异常值数量
【版本】 V1.0.0
【日期】 2019 10 16
"""
def BoxFeature(input_list):
# 获取箱体图特征
percentile = np.percentile(input_list, (25, 50, 75), interpolation='linear')
#以下为箱线图的五个特征值
Q1 = percentile[0]#上四分位数
Q2 = percentile[1]
Q3 = percentile[2]#下四分位数
IQR = Q3 - Q1#四分位距
ulim = Q3 + 1.5*IQR#上限 非异常范围内的最大值
llim = Q1 - 1.5*IQR#下限 非异常范围内的最小值
# llim = 0 if llim < 0 else llim
# out_list = [llim,Q1,Q2,Q3,ulim]
# 统计异常点个数
# 正常数据列表
right_list = []
Error_Point_num = 0
value_total = 0
average_num = 0
for item in input_list:
if item < llim or item > ulim:
Error_Point_num += 1
else:
right_list.append(item)
value_total += item
average_num += 1
average_value = value_total/average_num
# 特征值保留一位小数
out_list = [average_value,min(right_list), Q1, Q2, Q3, max(right_list)]
# print(out_list)
out_list = Save1point(out_list)
return out_list,Error_Point_num
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。

