详解Python可视化神器Yellowbrick使用
机器学习中非常重要的一环就是数据的可视化分析,从源数据的可视化到结果数据的可视化都离不开可视化工具的使用,sklearn+matplotlib的组合在日常的工作中已经满足了绝对大多数的需求,今天主要介绍的是一个基于sklearn和matplotlib模块进行扩展的可视化工具Yellowbrick。
Yellowbrick的官方文档在这里。Yellowbrick是由一套被称为"Visualizers"组成的可视化诊断工具组成的套餐,其由Scikit-Learn API延伸而来,对模型选择过程其指导作用。总之,Yellowbrick结合了Scikit-Learn和Matplotlib并且最好得传承了Scikit-Learn文档,对 你的 模型进行可视化!
Yellowbrick主要包含的组件如下:
Visualizers Visualizers也是estimators(从数据中习得的对象),其主要任务是产生可对模型选择过程有更深入了解的视图。从Scikit-Learn来看,当可视化数据空间或者封装一个模型estimator时,其和转换器(transformers)相似,就像"ModelCV" (比如 RidgeCV, LassoCV )的工作原理一样。Yellowbrick的主要目标是创建一个和Scikit-Learn类似的有意义的API。其中最受欢迎的visualizers包括: 特征可视化 Rank Features: 对单个或者两两对应的特征进行排序以检测其相关性 Parallel Coordinates: 对实例进行水平视图 Radial Visualization: 在一个圆形视图中将实例分隔开 PCA Projection: 通过主成分将实例投射 Feature Importances: 基于它们在模型中的表现对特征进行排序 Scatter and Joint Plots: 用选择的特征对其进行可视化 分类可视化 Class Balance: 看类的分布怎样影响模型 Classification Report: 用视图的方式呈现精确率,召回率和F1值 ROC/AUC Curves: 特征曲线和ROC曲线子下的面积 Confusion Matrices: 对分类决定进行视图描述 回归可视化 Prediction Error Plot: 沿着目标区域对模型进行细分 Residuals Plot: 显示训练数据和测试数据中残差的差异 Alpha Selection: 显示不同alpha值选择对正则化的影响 聚类可视化 K-Elbow Plot: 用肘部法则或者其他指标选择k值 Silhouette Plot: 通过对轮廓系数值进行视图来选择k值 文本可视化 Term Frequency: 对词项在语料库中的分布频率进行可视化 t-SNE Corpus Visualization: 用随机邻域嵌入来投射文档
这里以癌症数据集为例绘制ROC曲线,如下:
def testFunc1(savepath='Results/breast_cancer_ROCAUC.png'): ''' 基于癌症数据集的测试 ''' data=load_breast_cancer() X,y=data['data'],data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y) viz=ROCAUC(LogisticRegression()) viz.fit(X_train, y_train) viz.score(X_test, y_test) viz.poof(outpath=savepath)
结果如下:
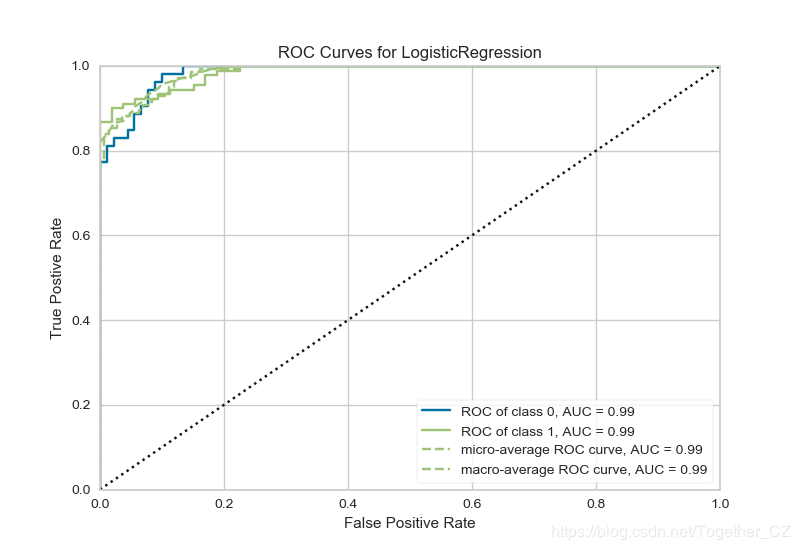
结果看起来也是挺美观的。
之后用平行坐标的方法对高维数据进行作图,数据集同上:
def testFunc2(savepath='Results/breast_cancer_ParallelCoordinates.png'): ''' 用平行坐标的方法对高维数据进行作图 ''' data=load_breast_cancer() X,y=data['data'],data['target'] print 'X_shape: ',X.shape #X_shape: (569L, 30L) visualizer=ParallelCoordinates() visualizer.fit_transform(X,y) visualizer.poof(outpath=savepath)
结果如下:
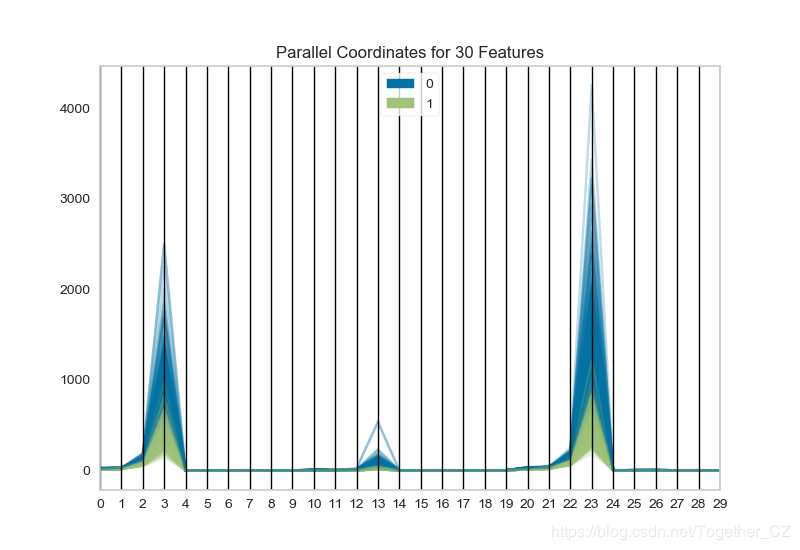
这个最初没有看明白什么意思,其实就是高维特征数据的可视化分析,这个功能还可以对原始数据进行采样,之后再绘图。
基于癌症数据集,使用逻辑回归模型来分类,绘制分类报告
def testFunc3(savepath='Results/breast_cancer_LR_report.png'): ''' 基于癌症数据集,使用逻辑回归模型来分类,绘制分类报告 ''' data=load_breast_cancer() X,y=data['data'],data['target'] model=LogisticRegression() visualizer=ClassificationReport(model) X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42) visualizer.fit(X_train,y_train) visualizer.score(X_test,y_test) visualizer.poof(outpath=savepath)
结果如下:
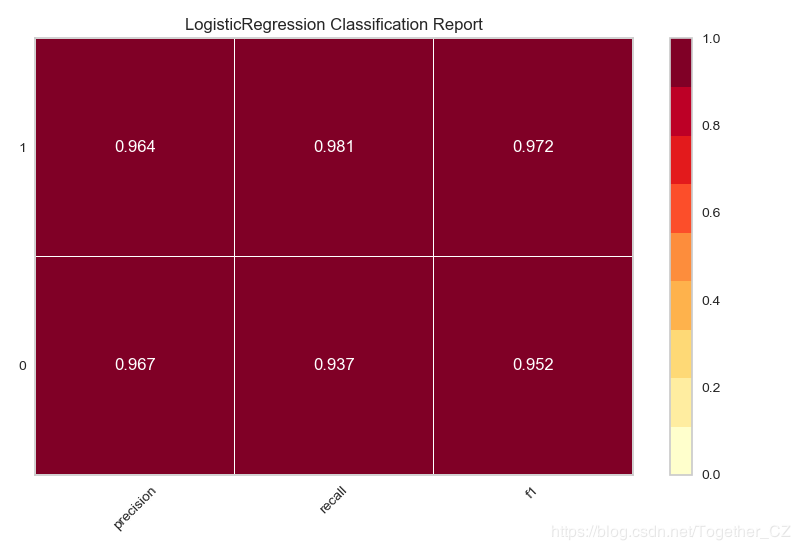
这样的结果展现方式还是比较美观的,在使用的时候发现了这个模块的一个不足的地方,就是:如果连续绘制两幅图片的话,第一幅图片就会累加到第二幅图片中去,多幅图片绘制亦是如此,在matplotlib中可以使用plt.clf()方法来清除上一幅图片,这里没有找到对应的API,希望有找到的朋友告知一下。
接下来基于共享单车数据集进行租借预测,具体如下:
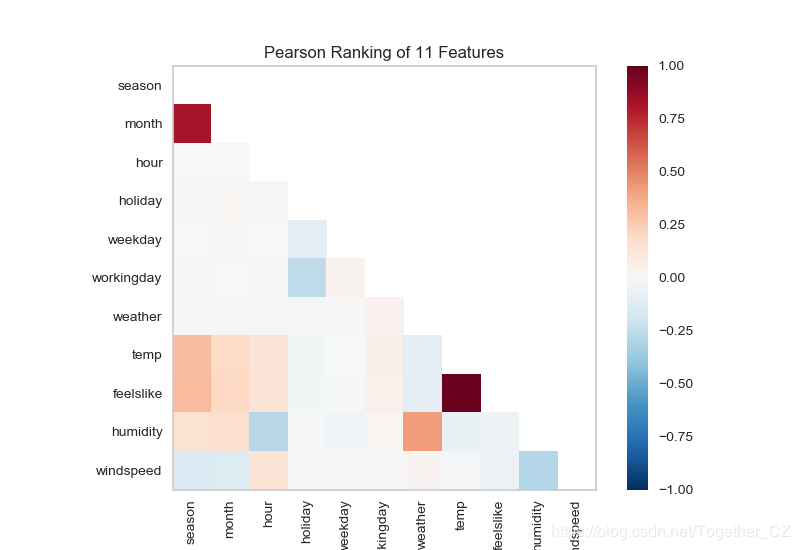
首先基于特征对相似度分析方法来分析共享单车数据集中两两特征之间的相似度
def testFunc5(savepath='Results/bikeshare_Rank2D.png'):
'''
共享单车数据集预测
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"
]]
y=data["riders"]
visualizer=Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.poof(outpath=savepath)
基于线性回归模型实现预测分析
def testFunc7(savepath='Results/bikeshare_LinearRegression_ResidualsPlot.png'):
'''
基于共享单车数据使用线性回归模型预测
'''
data = pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)
结果如下:

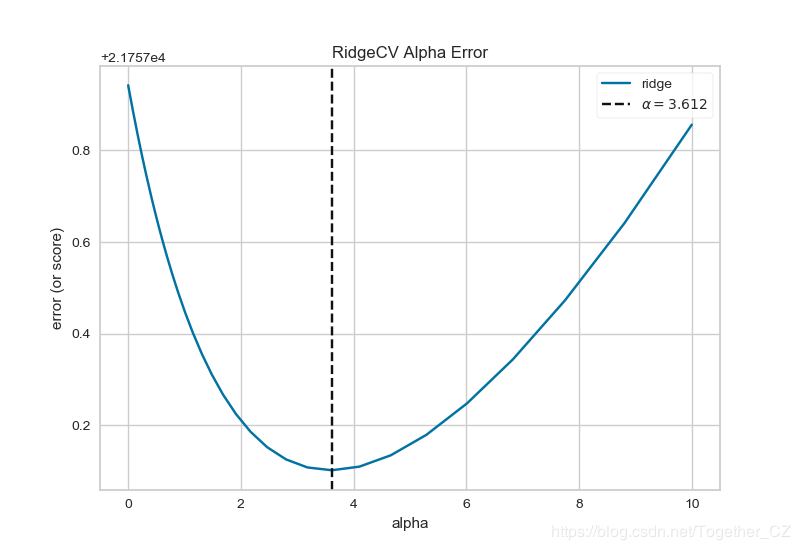
基于共享单车数据使用AlphaSelection
def testFunc8(savepath='Results/bikeshare_RidgeCV_AlphaSelection.png'):
'''
基于共享单车数据使用AlphaSelection
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
alphas=np.logspace(-10, 1, 200)
visualizer=AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.poof(outpath=savepath)
结果如下:
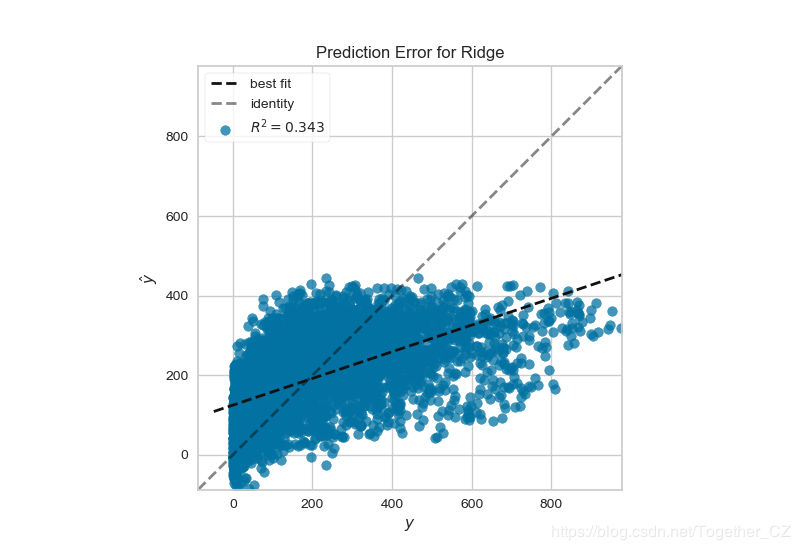
基于共享单车数据绘制预测错误图
def testFunc9(savepath='Results/bikeshare_Ridge_PredictionError.png'):
'''
基于共享单车数据绘制预测错误图
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=PredictionError(Ridge(alpha=3.181))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)
blog.csdn.net/Together_CZ/article/details/86640784
结果如下:
今天先记录到这里,之后有时间继续更新学习!
总结
以上所述是小编给大家介绍的Python可视化神器Yellowbrick使用,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!