JupyterNotebook设置Python环境的方法步骤
使用Python时,常遇到的一个问题就是Python和库的版本不同。Anaconda的env算是解决这个问题的一个好用的方法。但是,在使用Jupyter Notebook的时候,我却发现加载的仍然是默认的Python Kernel。这篇博客记录了如何在Jupyter Notebook中也能够设置相应的虚拟环境。
conda的虚拟环境
在Anaconda中,我们可以使用conda create -n your_env_name python=your_python_version的方法创建虚拟环境,并使用source activate your_env_name方式激活该虚拟环境,并在其中安装与默认(主)python环境不同的软件包等。
当激活该虚拟环境时,ipython下是可以正常加载的。但是打开Jupyter Notebook,会发现其加载的仍然是默认的Python kernel,而我们需要在notebook中也能使用新添加的虚拟环境。
解决方法
解决方法见这个帖子:Conda environments not showing up in Jupyter Notebook.
首先,安装nb_conda_kernels包:
conda install nb_conda_kernels
然后,打开Notebook,点击New,会出现当前所有安装的虚拟环境以供选择,如下所示。
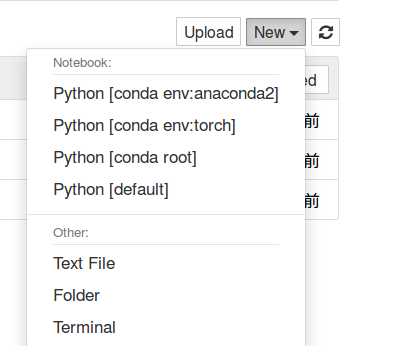
如果是已经编辑过的notebook,只需要打开该笔记本,在菜单栏中选择Kernel -> choose kernel -> your env kernel即可。

关于nb_conda_kernels的详细信息,可以参考其GitHub页面:nb_conda_kernels。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。