Python tensorflow实现mnist手写数字识别示例【非卷积与卷积实现】
本文实例讲述了Python tensorflow实现mnist手写数字识别。分享给大家供大家参考,具体如下:
非卷积实现
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
data_path = 'F:\CNN\data\mnist'
mnist_data = input_data.read_data_sets(data_path,one_hot=True) #offline dataset
x_data = tf.placeholder("float32", [None, 784]) # None means we can import any number of images
weight = tf.Variable(tf.ones([784,10]))
bias = tf.Variable(tf.ones([10]))
Y_model = tf.nn.softmax(tf.matmul(x_data ,weight) + bias)
#Y_model = tf.nn.sigmoid(tf.matmul(x_data ,weight) + bias)
'''
weight1 = tf.Variable(tf.ones([784,256]))
bias1 = tf.Variable(tf.ones([256]))
Y_model1 = tf.nn.softmax(tf.matmul(x_data ,weight1) + bias1)
weight1 = tf.Variable(tf.ones([256,10]))
bias1 = tf.Variable(tf.ones([10]))
Y_model = tf.nn.softmax(tf.matmul(Y_model1 ,weight1) + bias1)
'''
y_data = tf.placeholder("float32", [None, 10])
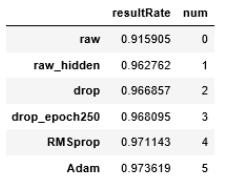
loss = tf.reduce_sum(tf.pow((y_data - Y_model), 2 ))#92%-93%
#loss = tf.reduce_sum(tf.square(y_data - Y_model)) #90%-91%
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init) # reset values to wrong
for i in range(100000):
batch_xs, batch_ys = mnist_data.train.next_batch(50)
sess.run(train, feed_dict = {x_data: batch_xs, y_data: batch_ys})
if i%50==0:
correct_predict = tf.equal(tf.arg_max(Y_model,1),tf.argmax(y_data,1))
accurate = tf.reduce_mean(tf.cast(correct_predict,"float"))
print(sess.run(accurate,feed_dict={x_data:mnist_data.test.images,y_data:mnist_data.test.labels}))
卷积实现
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
data_path = 'F:\CNN\data\mnist'
mnist_data = input_data.read_data_sets(data_path,one_hot=True) #offline dataset
x_data = tf.placeholder("float32", [None, 784]) # None means we can import any number of images
x_image = tf.reshape(x_data, [-1,28,28,1])
w_conv = tf.Variable(tf.ones([5,5,1,32])) #weight
b_conv = tf.Variable(tf.ones([32])) #bias
h_conv = tf.nn.relu(tf.nn.conv2d(x_image , w_conv,strides=[1,1,1,1],padding='SAME')+ b_conv)
h_pool = tf.nn.max_pool(h_conv,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
w_fc = tf.Variable(tf.ones([14*14*32,1024]))
b_fc = tf.Variable(tf.ones([1024]))
h_pool_flat = tf.reshape(h_pool,[-1,14*14*32])
h_fc = tf.nn.relu(tf.matmul(h_pool_flat,w_fc) +b_fc)
W_fc = w_fc = tf.Variable(tf.ones([1024,10]))
B_fc = tf.Variable(tf.ones([10]))
Y_model = tf.nn.softmax(tf.matmul(h_fc,W_fc) +B_fc)
y_data = tf.placeholder("float32",[None,10])
loss = -tf.reduce_sum(y_data * tf.log(Y_model))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs,batch_ys =mnist_data.train.next_batch(5)
sess.run(train_step,feed_dict={x_data:batch_xs,y_data:batch_ys})
if i%50==0:
correct_prediction = tf.equal(tf.argmax(Y_model,1),tf.argmax(y_data,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
print(sess.run(accuracy,feed_dict={x_data:mnist_data.test.images,y_data:mnist_data.test.labels}))
更多关于Python相关内容可查看本站专题:《Python数学运算技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。