浅谈Tensorflow 动态双向RNN的输出问题
tf.nn.bidirectional_dynamic_rnn()
函数:
def bidirectional_dynamic_rnn( cell_fw, # 前向RNN cell_bw, # 后向RNN inputs, # 输入 sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度) initial_state_fw=None, # 前向的初始化状态(可选) initial_state_bw=None, # 后向的初始化状态(可选) dtype=None, # 初始化和输出的数据类型(可选) parallel_iterations=None, swap_memory=False, time_major=False, # 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`. # 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`. scope=None )
其中,
outputs为(output_fw, output_bw),是一个包含前向cell输出tensor和后向cell输出tensor组成的元组。假设
time_major=false,tensor的shape为[batch_size, max_time, depth]。实验中使用tf.concat(outputs, 2)将其拼接。
output_states为(output_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的元组。
output_state_fw和output_state_bw的类型为LSTMStateTuple。
LSTMStateTuple由(c,h)组成,分别代表memory cell和hidden state。
返回值:
元组:(outputs, output_states)
这里还有最后的一个小问题,output_states是一个元组的元组,处理方法是用c_fw,h_fw = output_state_fw和c_bw,h_bw = output_state_bw,最后再分别将c和h状态concat起来,用tf.contrib.rnn.LSTMStateTuple()函数生成decoder端的初始状态
def encoding_layer(rnn_size,sequence_length,num_layers,rnn_inputs,keep_prob):
# rnn_size: rnn隐层节点数量
# sequence_length: 数据的序列长度
# num_layers:堆叠的rnn cell数量
# rnn_inputs: 输入tensor
# keep_prob:
'''Create the encoding layer'''
for layer in range(num_layers):
with tf.variable_scope('encode_{}'.format(layer)):
cell_fw = tf.contrib.rnn.LSTMCell(rnn_size,initializer=tf.random_uniform_initializer(-0.1,0.1,seed=2))
cell_fw = tf.contrib.rnn.DropoutWrapper(cell_fw,input_keep_prob=keep_prob)
cell_bw = tf.contrib.rnn.LSTMCell(rnn_size,initializer=tf.random_uniform_initializer(-0.1,0.1,seed=2))
cell_bw = tf.contrib.rnn.DropoutWrapper(cell_bw,input_keep_prob = keep_prob)
enc_output,enc_state = tf.nn.bidirectional_dynamic_rnn(cell_fw,cell_bw,
rnn_inputs,sequence_length,dtype=tf.float32)
# join outputs since we are using a bidirectional RNN
enc_output = tf.concat(enc_output,2)
return enc_output,enc_statetf.nn.dynamic_rnn()
tf.nn.dynamic_rnn的返回值有两个:outputs和state
为了描述输出的形状,先介绍几个变量,batch_size是输入的这批数据的数量,max_time就是这批数据中序列的最长长度,如果输入的三个句子,那max_time对应的就是最长句子的单词数量,cell.output_size其实就是rnn cell中神经元的个数。
例子来说明其用法,假设你的RNN的输入input是[2,20,128],其中2是batch_size,20是文本最大长度,128是embedding_size,可以看出,有两个example,我们假设第二个文本长度只有13,剩下的7个是使用0-padding方法填充的。dynamic返回的是两个参数:outputs,state,其中outputs是[2,20,128],也就是每一个迭代隐状态的输出,state是由(c,h)组成的tuple,均为[batch,128]。
outputs. outputs是一个tensor
如果time_major==True,outputs形状为 [max_time, batch_size, cell.output_size ](要求rnn输入与rnn输出形状保持一致)
如果time_major==False(默认),outputs形状为 [ batch_size, max_time, cell.output_size ]
state. state是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下state的形状为 [batch_size, cell.output_size ],但当输入的cell为BasicLSTMCell时,state的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
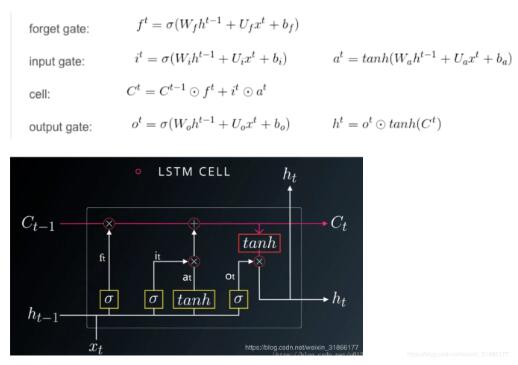
这里有关于LSTM的结构问题:
以上这篇浅谈Tensorflow 动态双向RNN的输出问题就是小编分享给大家的全部内容了,希望能给大家一个参考。