相关文章

Python爬虫 bilibili视频弹幕提取过程详解
两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 import requests from lxm...

Python即时网络爬虫项目启动说明详解
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心。 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级...
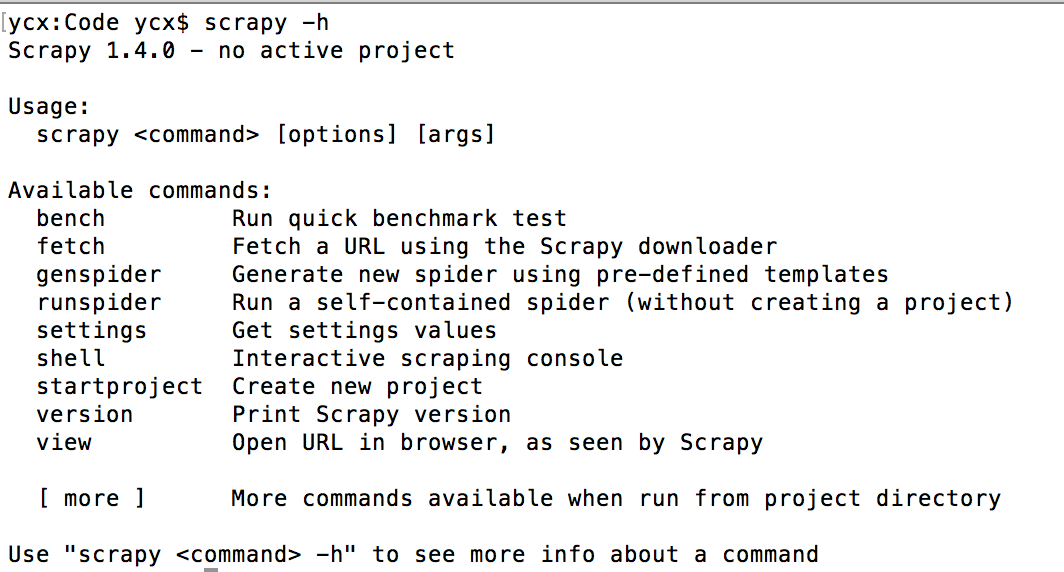
Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令。分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令。 全局命令不需要依靠Scra...
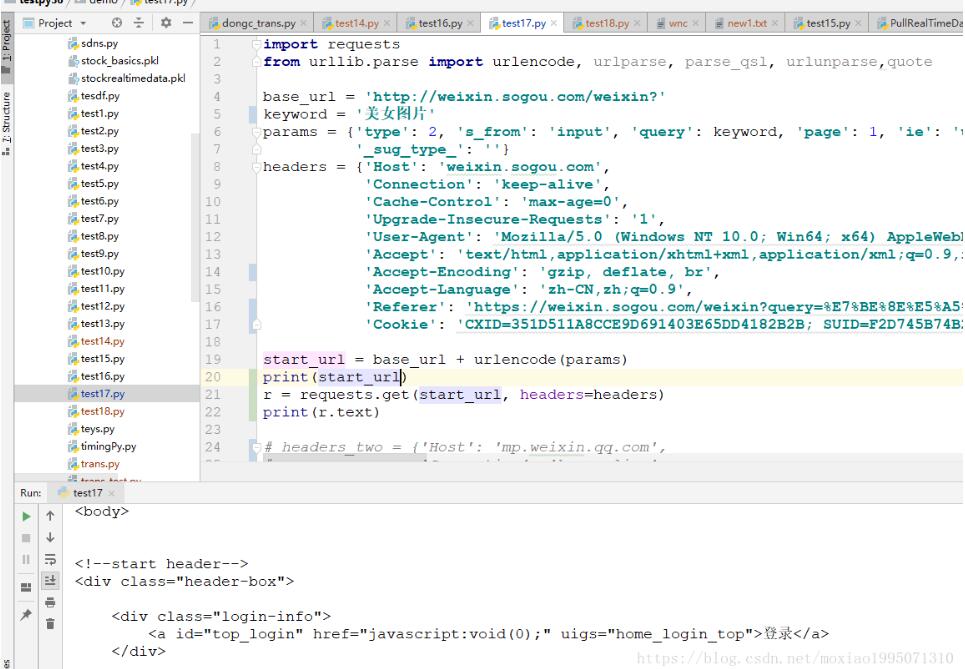
python爬取微信公众号文章的方法
最近在学习Python3网络爬虫开发实践(崔庆才 著)刚好也学习到他使用代理爬取公众号文章这里,但是照着他的代码写,出现了一些问题。在这里我用到了这本书的前面讲的一些内容进行了完善。(作...
Python基于多线程实现抓取数据存入数据库的方法
本文实例讲述了Python基于多线程实现抓取数据存入数据库的方法。分享给大家供大家参考,具体如下: 1. 数据库类 """ 使用须知: 代码中数据表名 aces ,需要更改该数据表名...