Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令。分享给大家供大家参考,具体如下:
在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令。
全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目命令必须要在Scrapy项目中才可以运行
全局命令
全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示:
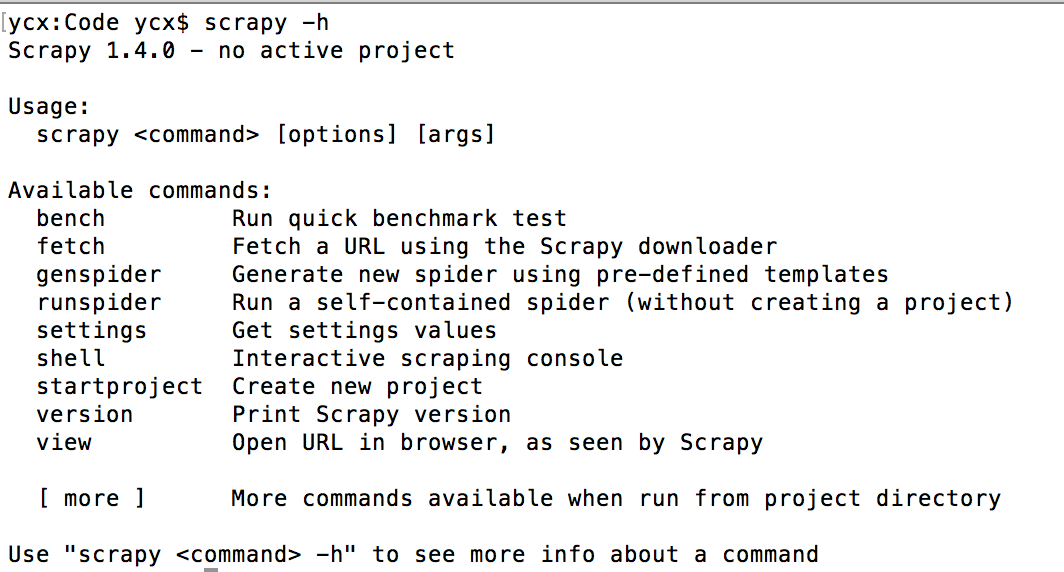
可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch、runspider、settings、shell、startproject、version、view。
fetch命令
fetch命令主要用来显示爬虫爬取的过程.如下图所示:
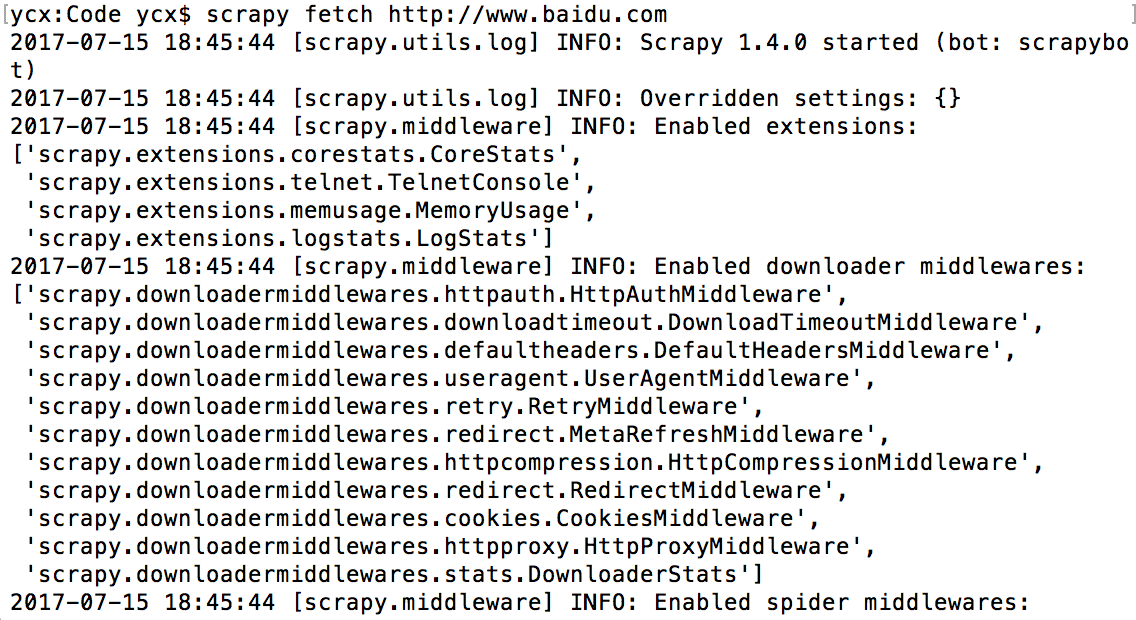
在使用fetch命令时,同样可以使用某些参数进行相应的控制。那么fetch有哪些相关参数可以使用呢?我们可以通过scrpy fetch -h列出所有可以使用的fetch相关参数。比如我们可以使用–headers显示头信息,也可以使用–nolog控制不显示日志信息,还可以使用–spider=SPIDER参数来控制使用哪个爬虫,通过–logfile=FILE指定存储日志信息的文件,通过–loglevel=LEVEL控制日志等级。举个栗子:
# 显示头信息,并且不显示日志信息 scrpay -fetch --headers --nolog http://www.baidu.com
sunspider命令
通过runspider命令可以不依托scrapy的爬虫项目,直接运行一个爬虫文件
# first.py为自定义的一个爬虫文件 scrapy runspider first.py
settings命令
在scrapy项目所在的目录中使用settings命令查看的使用对应的项目配置信息,如果在scrapy项目所在的目录外使用settings命令查看的Scrapy默认的配置信息
# 在项目中使用此命令打印的为BOT_NAME对应的值,即scrapy项目名称。 # 在项目外使用此命令打印的为scrapybot scrapy settings --get BOT_NAME
shell命令
通过shell命令可以启动Scrapy的交互终端。
Scrapy的交互终端经常在开发以及调试的时候用到,使用Scrapy的交互终端可以实现在不启动Scrapy爬虫的情况下,对网站响应进行调试,同样,在该交互终端下,我们也可以写一些Python代码进行相应测试。
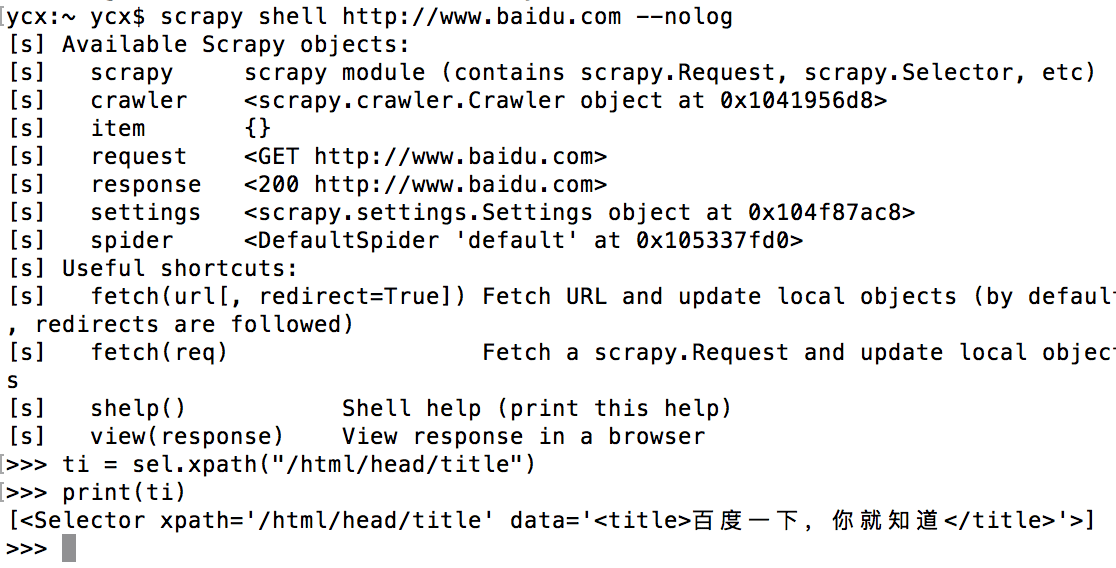
在>>>后面可以输入交互命令以及相应的代码
startproject命令
用于创建scrapy项目
version命令
查看scrapy版本
view命令
用于下载某个网页,然后通过浏览器查看
项目命令
bench命令
测试本地硬件的性能
scrapy bench
genspider命令
用于创建爬虫文件,这是一种快速创建爬虫文件的方式。
# scrpay genspider -t 基本格式 # basic 模板 # baidu.com 爬取的域名 scrapy genspider -t basic xxx baidu.com
此时在spider文件夹下会生成一个以xxx命名的py文件。可以使用scrapy genspider -l查看所有可用爬虫模板。当前可用的爬虫模板有:basic、crawl、csvfeed、xmlfeed
check命令
使用check命令可以实现对某个爬虫文件进行合同检查,即测试.
# xxx为爬虫名 scrapy check xxx
crawl命令
启动某个爬虫
# xxx为爬虫名 scrapy crawl xxx
list命令
列出当前可使用的爬虫文件
scrapy list
edit命令
编辑爬虫文件
scrapy edit xxx
parse命令
通过parse命令,我们可以实现获取指定的URL网址,并使用对应的爬虫文件进行处理和分析
日志等级
| 等级名 | 含义 |
|---|---|
| CRITICAL | 发生了最严重的错误 |
| ERROR | 发生了必须立即处理的错误 |
| WARNING | 出现了一些警告信息,即存在潜在错误 |
| INFO | 输出一些提示显示 |
| DEBUG | 输出一些调试信息 |
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。