Python爬虫番外篇之Cookie和Session详解
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解
什么是Cookie
其实简单的说就是当用户通过http协议访问一个服务器的时候,这个服务器会将一些Name/Value键值对返回给客户端浏览器,并将这些数据加上一些限制条件。在条件符合时,这个用户下次再访问服务器的时候,数据又被完整的带给服务器。
因为http是一种无状态协议,用户首次访问web站点的时候,服务器对用户一无所知。而Cookie就像是服务器给每个来访问的用户贴的标签,而这些标签就是对来访问的客户端的独有的身份的一个标识,这里就如同每个人的身份证一样,带着你的个人信息。而当一个客户端第一次连接过来的时候,服务端就会给他打一个标签,这里就如同给你发了一个身份证,当你下载带着这个身份证来的时候,服务器就知道你是谁了。所以Cookie是存在客户端的,这里其实就是在你的浏览器中。
Cookie中包含了一个由名字=值(name=value)这样的信息构成的任意列表,通过Set-Cookie或Set-Cookie2HTTP响应(扩展)首部将其贴到客户端身上。如下图例子所示:
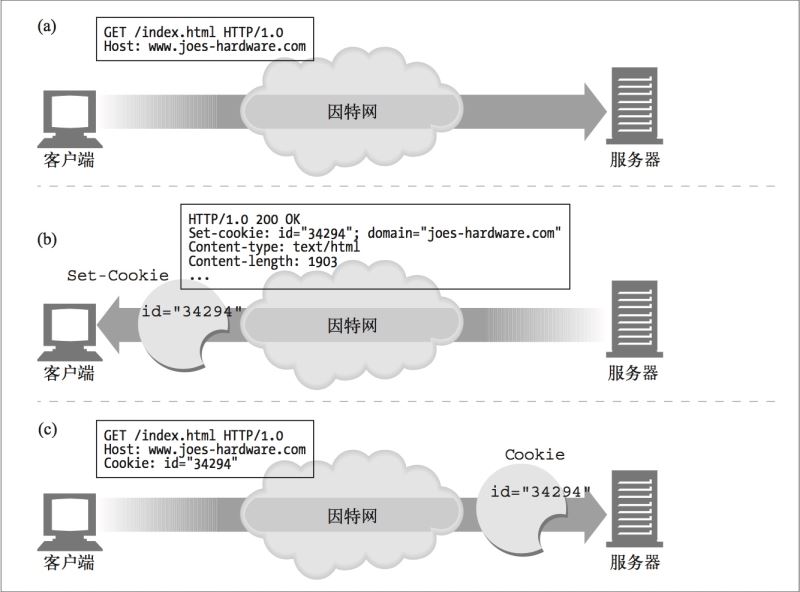
其实这里有一个非常典型的应用,就是关于你登录很多网站的账号信息,你让记住密码之后,一段时间内,不需要输入密码,每次都是登录状态
Cookie的分类
这里Cookie主要分为两种:
会话Cookie:不设置过期时间,保存在浏览器的内存中,关闭浏览器,Cookie便被销毁
普通Cookie:设置了过期时间,保存在硬盘上
Cookie属性
因为最开始的cookie是网景公司定义的,后来又有了RFC版本所以当前的Cookie有两个版本:Version0Version1他们有两种设置响应头的标识,分别是:Set-Cookie和Set-Cookie2,这也造成了一些属性的不同,这里需要注意:常用的为Version0
Version0的属性
NAME=Value:键值对设置要保存的Name/Value,这里的name不能喝其他属性的名字一样
Expires:过期时间
Domain:生成该Cookie的域名
Path:该Cookie是在当前的哪个路径下生成
Secure:如果设置了这个属性,那么只会在SSH连接时才会回传该Cookie
Version1的属性
Name=VALUE:键值对设置要保存的Name/Value,这里的name不能喝其他属性的名字一样
Comment:主是想,用于说明该Cookie有什么用途
CommentURL:该服务器为此COokie提供URI注释
Discard:是否在回话结束丢弃该Cookie,默认为false
Domain:生成该Cookie的域名
Max-Age:最大失效时间,与Version0不同的是这里设置的是在多少秒后失效
Path:该Cookie是在当前的哪个路径下生成
Port:该Cookie在什么端口下可以回传服务端,如果有多个端口,以逗号隔开
Secure:如果设置了这个属性,那么只会在SSH连接时才会回传该Cookie
关于Session
上面我们知道了Cookie可以让服务器端跟踪每个客户端的访问,但是每次客户端的访问都必须传回这些Cookie,如果Cookie很多,这无形地增加了客户端与服务端的数据传输量,而Session的出现正是为了解决这个问题。
同一个客户端每次和服务端交互时,不需要每次都传回所有的Cookie值,而是只要传回一个ID这个ID是客户端第一次访问服务器的时候生成的,而且每个客户端是唯一的。这样每个客户端就有了一个唯一的ID,客户端只要传回这个ID就行了,这个ID通常是NANE为JSESIONID的一个Cookie。所以Session其实是利用Cookie进行信息处理的。
cookie和session的共同之处在于:cookie和session都是用来跟踪浏览器用户身份的会话方式。
cookie和session的区别是:cookie数据保存在客户端,session数据保存在服务器端。
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session,当然也没有绝对的安全,只是相对cookie,session更加安全
session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
cookie和session各有优缺点,所以将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
总结
以上就是本文关于Python爬虫番外篇之Cookie和Session详解的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!