Python3爬虫学习入门教程
本文实例讲述了Python3爬虫相关入门知识。分享给大家供大家参考,具体如下:
在网上看到大多数爬虫教程都是Python2的,但Python3才是未来的趋势,许多初学者看了Python2的教程学Python3的话很难适应过来,毕竟Python2.x和Python3.x还是有很多区别的,一个系统的学习方法和路线非常重要,因此我在联系了一段时间之后,想写一下自己的学习过程,分享一下自己的学习经验,顺便也锻炼一下自己。
一、入门篇
这里是Python3的官方技术文档,在这里需要着重说一下,语言的技术文档是用来查的,不是用来学习的,真的没必要把文档背下来,这样学习效率真的很低,不如片学边做,在实践中才会学到东西,不然即使你背会了文档,你仍然很难做出什么项目来,我当初就是在这上面,走了很多弯路,在这里推荐W3cscjool里面的教程非常不错,学习与实践相结合。
1. 少废话,先看东西
第一个例子:爬取知乎首页源码。
#-*-coding:utf-8 -*-
import urllib.request
url = "http://www.zhihu.com"
page_info = urllib.request.urlopen(url).read()
page_info = page_info.decode('utf-8')
print(page_info)
运行结果:
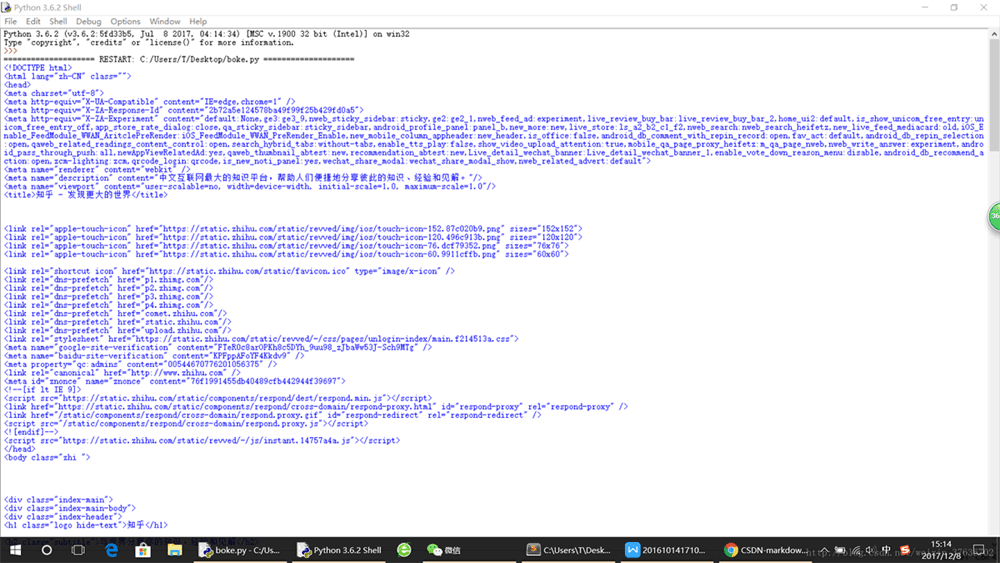
运行之后,在IDLE shell里面知乎网站首页的源代码就会被读出来啦Blahblahblah~~~
爬虫定义:
网络爬虫(Web Spider),又被称为网页蜘蛛,是一种按照一定的规则,自动地抓取网站信息的程序或者脚本。
简介:
网络蜘蛛是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从 网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
爬虫流程:
①先由urllib的request打开Url得到网页html文档——②浏览器打开网页源代码分析元素节点——③通过Beautiful Soup(后面会讲到)或则正则表达式提取想要的数据——④存储数据到本地磁盘或数据库(抓取,分析,存储)
urllib和urllib2
python2.x里urllib2库,在python3.x里,urllib2改名为urllib,被分成一些子模块:urllib.request, urllib.parse和urllib.error。尽管函数名称大多数和原来一样,但是在用新的urllib库时需要注意哪些函数被移动到子模块里了。
urllib是python的标准库,包含了从网络请求数据,处理cookie,甚至改变像请求头和用户代理这些元数据的函数。
urlopen用来打开并读取一个从网络获取的远程对象。它可以轻松读取HTML文件、图像文件或其他任何文件流。
url = "http://www.zhihu.com" page_info = urllib.request.urlopen(url).read()
urllib.request是urllib的一个子模块,可以打开和处理一些复杂的网址
decode('utf-8')用来将页面转换成utf-8的编码格式,否则会出现乱码
page_info = page_info.decode('utf-8')
print(page_info)
urllib.request.urlopen()方法实现了打开url,并返回一个 http.client.HTTPResponse对象,通过http.client.HTTPResponse的read()方法,获得response body,转码最后通过print()打印出来.
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。