python爬虫入门教程之点点美女图片爬虫代码分享
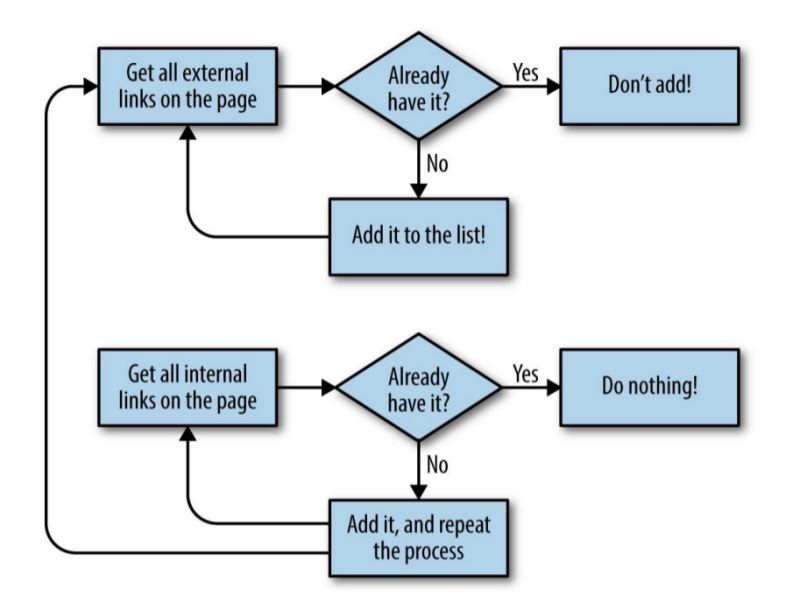
继续鼓捣爬虫,今天贴出一个代码,爬取点点网「美女」标签下的图片,原图。
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:点点美女图片爬虫
# 版本:0.2
# 作者:zippera
# 日期:2013-07-26
# 语言:Python 2.7
# 说明:能设置下载的页数
#---------------------------------------
import urllib2
import urllib
import re
pat = re.compile('<div class="feed-big-img">\n.*?imgsrc="(ht.*?)\".*?')
nexturl1 = "http://www.diandian.com/tag/%E7%BE%8E%E5%A5%B3?page="
count = 1
while count < 2:
print "Page " + str(count) + "\n"
myurl = nexturl1 + str(count)
myres = urllib2.urlopen(myurl)
mypage = myres.read()
ucpage = mypage.decode("utf-8") #转码
mat = pat.findall(ucpage)
if len(mat):
cnt = 1
for item in mat:
print "Page" + str(count) + " No." + str(cnt) + " url: " + item + "\n"
cnt += 1
fnp = re.compile('(\w{10}\.\w+)$')
fnr = fnp.findall(item)
if fnr:
fname = fnr[0]
urllib.urlretrieve(item, fname)
else:
print "no data"
count += 1
使用方法:新建一个文件夹,把代码保存为name.py文件,运行python name.py就可以把图片下载到文件夹。