K-近邻算法的python实现代码分享
k-近邻算法概述:
所谓k-近邻算法KNN就是K-Nearest neighbors Algorithms的简称,它采用测量不同特征值之间的距离方法进行分类
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
k-近邻算法分析
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型
k-近邻算法工作原理:
它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的的分类,作为新数据的分类。
k-近邻算法实现过程:
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
k-近邻算法python代码实现:
编辑kNN.py文件代码如下:
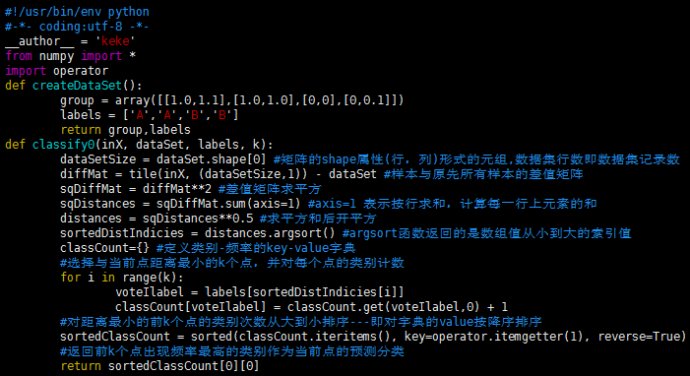
编辑完成后保存,linux下确保当前路径为存储kNN.py文件的位置,进入python开发环境开始测试:
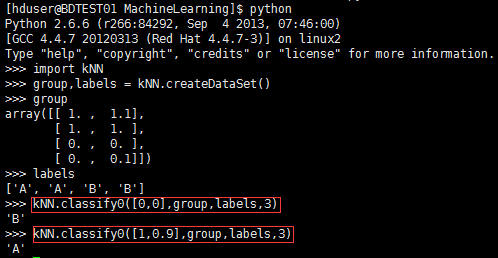
上图给出了点[0,0]、[1,0.9]的测试输出分类结果分别为B、A。至此,我们已经构造完成了一个分类器,使用这个分类器可以完成很多分类任务。从这个实例出发,构造使用分类算法将会更加容易。
分类器测试评估:
为了测试分类器的效果,需要对分类器做出评估,我们可以通过大量的测试数据得到分类器的错误率——分类器给出错误结果的次数除以测试执行的总数。错误率是常用的评估方法,主要用于评估分类器在某个数据集上的执行效果。完美分类器的错误率为0,最差分类器的错误率是1.0,在这种情况下,分类器根本就无法找到一个正确答案。
结束语:
本文首先对kNN做了简单介绍,通过了解其工作原理和实现流程,并使用k-近邻算法构造了分类器。我们也可以检验分类器给出的答案是否符合我们的预期。此外,还可以对分类器做大量的测试,并以错误率来评估该分类器的分类效果。
以上就是本文关于K-近邻算法的python实现代码分享的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题。如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
