1分钟快速生成用于网页内容提取的xslt
1分钟快速生成用于网页内容提取的xslt,具体内容如下
1、项目背景
在《Python即时网络爬虫项目说明》一文我们说过要做一个通用的网络爬虫,而且能节省程序员大半的时间,而焦点问题就是提取器使用的抓取规则需要快速生成。在python使用xslt提取网页数据一文,我们已经看到这个提取规则是xslt程序,在示例程序中,直接把一长段xslt赋值给变量,但是没有讲这一段xslt是怎么来的。
网友必然会质疑:这个xslt这么长,编写不是要花很长时间?
实际情况是,这个xslt是通过GooSeeker的MS谋数台的直观标注功能自动生成的,熟练的话1分钟就搞定了。
2、MS谋数台能做什么
MS谋数台有个图形化界面,把一系列html解析工具集成在一起,包括:
- 基于直观标注自动生成XSLT
- 即时测试XSLT的正确性
- 树状的DOM结构展示
- 剖析某个DOM节点的属性
- 为DOM节点生成XPath,可选择定位到class、或者id、或者绝对定位
- 根据xpath搜索DOM节点
MS谋数台界面分成三部分:DOM数窗口、内嵌浏览器窗口、工作台。在工作台上定义xslt转换规则。
3、用MS谋数台生成XSLT
假设我们要抓取论坛帖子列表,下面一步步讲解操作方法:
第一步,打开GooSeeker的MS谋数台,输入要抓取的网址
第二步,在MS谋数台的浏览器显示窗口里,直接选取要提取的内容,并且起个名字,点击确认
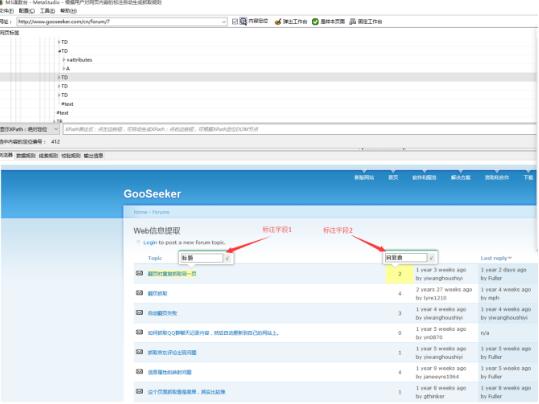
第三步,点击工作台的“测试”按钮,xslt就生成了,在“数据规则”窗口显示出来
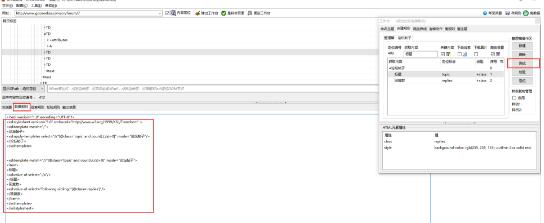
通过以上的操作,不用编程,用图形化界面直接在页面上标注,1分钟就可以生成xslt
4、怎样使用XSLT
在python使用xslt提取网页数据一文,我们把生成xslt作为一个字符串交给程序,给人感觉好像一下子回到了史前文明,前面讲的那么好,最后用了很原始的拷贝。其实不然,那个只是一个例子。在《python即时网络爬虫项目: 内容提取器的定义》一文已经初见端倪了,有多种注入xslt的方式,最自动化的方式是api,将在后续文章中详细讲解。
5、文档修改历史
2016-05-28:V3.0,增加第二章
2016-05-26:V2.0,增补文字说明
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
