python处理数据,存进hive表的方法
首先,公司的小组长给了我一个任务,把一个txt的文件中的部分内容,存进一个在hive中已有的表的相同结构的表中。所以我的流程主要有三个,首先,把数据处理成和hive中表相同结构的数据,然后仿照已有的hive中表的结构再创建一张新的数据表,最后把本地的txt文件上传到hive中新建的数据表中。
1:已有的数据表的结构和在hive表中的结构完全对不上,下面的图是原来hive中表的结构和小组长给我的txt中表的结构:
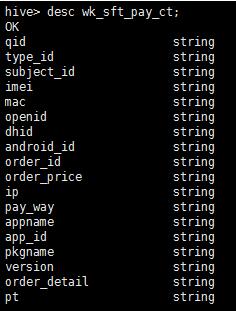

大家可以看出,我们原来的hive中表的字段一共有17个,而组长给我的表中的字段一共有9个,其中最后一个为json结构,而且顺序还不对,所以我们要进行筛选,把对应上的字段放到相应位置,对应不上的字段写成空。

大家要注意几个地方,原来的数据是按照tab来划分的,所以我们要数好对应的tab的数目,好来计算出来数据的实际的位置信息,然后我们按照原来hive表中的数据顺序,重新排列我们新建表的数据的顺序,下面给大家看看结果:

其中line[0]=null,line[1]=102,大家以此类推。
3:我们把本地的txt文件导入到hive表中。首先我们要新建一个和原来hive表中相同结构的数据表,然后把我们的数据导入到表中,
hive> creat table new_sft(x1 string,x2 string ,...,xn string) partitioned by (d string);
建好表之后,把数据导入到新表之中:
hive> load data local inpath‘/home/opendev/1.txt' into table new_sft;
最后给大家看看我的最终的结果:

以上这篇python处理数据,存进hive表的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。
