Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能。分享给大家供大家参考,具体如下:
python3爬虫之爬取百姓网列表并保存为json文件。这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手。
首先需要安装python3。如果还没有安装,可参考本站python3安装与配置相关文章。
首先需要安装requests和lxml和json三个模块
需要手动创建d.json文件
代码
import requests
from lxml import etree
import json
#构造头文件,模拟浏览器访问
url="http://xian.baixing.com/meirongfuwu/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36','referer':url}
response=requests.get(url,headers=headers)
body=response.text #获取网页内容
html=etree.HTML(body,etree.HTMLParser())
gethtml=html.xpath('//div[contains(@class,"media-body-title")]')
# 存储为数组list
jsondata = []
for item in gethtml:
jsonone={}
jsonone['title']=item.xpath('.//a[contains(@class,"ad-title")]/text()')[0]
jsonone['url']=item.xpath('.//a[contains(@class,"ad-title")]/attribute::href')[0]
jsonone['phone']=item.xpath('.//button[contains(@class,"contact-button")]/attribute::data-contact')[0]
jsondata.append(jsonone)
# 保存为json
with open("./d.json",'w',encoding='utf-8') as json_file:
json.dump(jsondata,json_file,ensure_ascii=False)
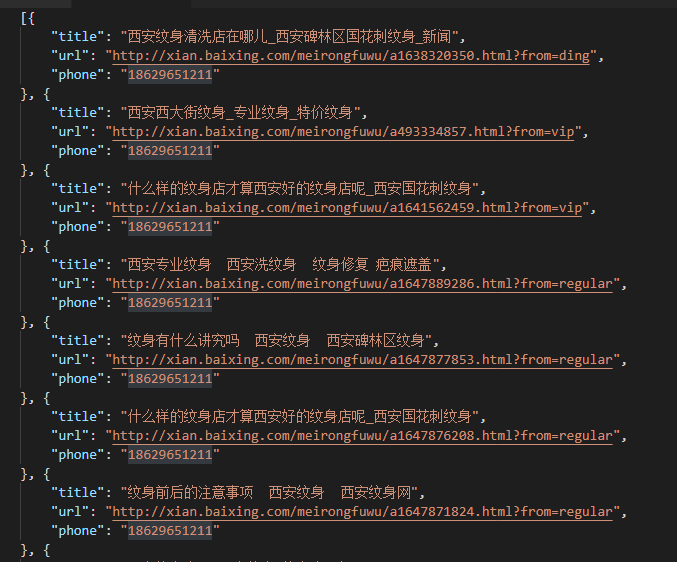
结果
PS:这里再为大家推荐几款比较实用的json在线工具供大家参考使用:
在线JSON代码检验、检验、美化、格式化工具:
http://tools.jb51.net/code/json
JSON在线格式化工具:
http://tools.jb51.net/code/jsonformat
在线XML/JSON互相转换工具:
http://tools.jb51.net/code/xmljson
json代码在线格式化/美化/压缩/编辑/转换工具:
http://tools.jb51.net/code/jsoncodeformat
在线json压缩/转义工具:
http://tools.jb51.net/code/json_yasuo_trans
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。