Python学习笔记之抓取某只基金历史净值数据实战案例
本文实例讲述了Python抓取某只基金历史净值数据。分享给大家供大家参考,具体如下:
http://fund.eastmoney.com/f10/jjjz_519961.html
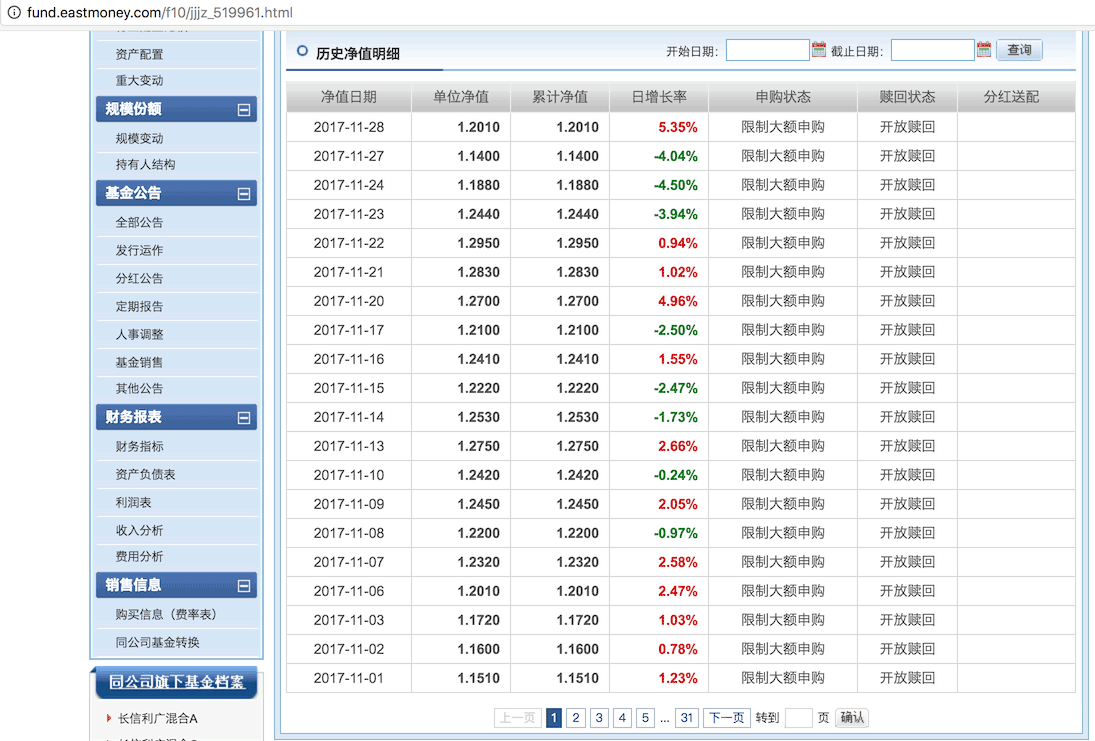
1、接下来,我们需要动手把这些html抓取下来(这部分知识我们之前已经学过,现在不妨重温)
# coding: utf-8
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from threading import Thread,Lock
import os
import csv
# 下面是利用 selenium 抓取html页面的代码
# 初始化函数
def initSpider():
driver = webdriver.PhantomJS(executable_path=r"你phantomjs可执行文件的绝对路径")
driver.get("http://fund.eastmoney.com/f10/jjjz_519961.html") # 要抓取的网页地址
# 找到"下一页"按钮,就可以得到它前面的一个label,就是总页数
getPage_text = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/label[text()='下一页']/preceding-sibling::label[1]").get_attribute("innerHTML")
# 得到总共有多少页
total_page = int("".join(filter(str.isdigit, getPage_text)))
# 返回
return (driver,total_page)
# 获取html内容
def getData(myrange,driver,lock):
for x in myrange:
# 锁住
lock.acquire()
tonum = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pnum']") # 得到 页码文本框
jumpbtn = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pgo']") # 跳转到按钮
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpbtn.click() # 点击按钮
# 抓取
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pagebar").find_element_by_xpath("div[@class='pagebtns']/label[@value={0} and @class='cur']".format(x)) != None)
# 保存到项目中
with open("../htmls/details/{0}.txt".format(x), 'wb') as f:
f.write(driver.find_element_by_id("jztable").get_attribute("innerHTML").encode('utf-8'))
f.close()
# 解锁
lock.release()
# 开始抓取函数
def beginSpider():
# 初始化爬虫
(driver, total_page) = initSpider()
# 创建锁
lock = Lock()
r = range(1, int(total_page)+1)
step = 10
range_list = [r[x:x + step] for x in range(0, len(r), step)] #把页码分段
thread_list = []
for r in range_list:
t = Thread(target=getData, args=(r,driver,lock))
thread_list.append(t)
t.start()
for t in thread_list:
t.join() # 这一步是需要的,等待线程全部执行完成
print("抓取完成")
# #################上面代码就完成了 抓取远程网站html内容并保存到项目中的 过程
需要说明一下这3个函数:
initSpider函数,初始化了selenium的webdriver对象,并且先获取到我们需要抓取页面的总页码数。
getData函数,有3个参数,myrange我们还是要分段抓取,之前我们学过多进程抓取,这里我们是多线程抓取;lock参数用来锁住线程的,防止线程冲突;driver就是我们在initSpider函数中初始化的webdriver对象。
在getData函数中,我们循环myrange,把抓取到的html内容保存到了项目目录中。
beginSpider函数,我们在此函数中给总页码分段,并且创建线程,调用getData。
所以最后执行:
beginSpider()
就开始抓取 http://fund.eastmoney.com/f10/jjjz_519961.html 这个基金的”历史净值明细”,共有31个页面。
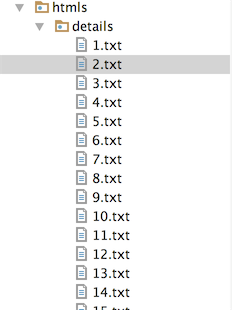
2、根据已经学过的python和mysql交互的知识,我们也可以再把这些数据 写入到数据表中。
这里就不再赘述,给出基金详细表结构:
CREATE TABLE `fund_detail` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `fcode` varchar(10) NOT NULL DEFAULT '' COMMENT '基金代码', `fdate` datetime DEFAULT NULL COMMENT '基金日期', `NAV` decimal(10,4) DEFAULT NULL COMMENT '单位净值', `ACCNAV` decimal(10,4) DEFAULT NULL COMMENT '累计净值', `DGR` varchar(20) DEFAULT NULL COMMENT '日增长率', `pstate` varchar(20) DEFAULT NULL COMMENT '申购状态', `rstate` varchar(20) DEFAULT NULL COMMENT '赎回状态', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='基金详细数据表';
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。