Django生成PDF文档显示网页上以及PDF中文显示乱码的解决方法
项目地址:https://github.com/PythonerKK/django-generate-pdf/tree/master
这个demo实现了通过用户输入自己的个人信息生成一份简历pdf,来阐述如何使用Django的HttpResponse生成PDF的文档。
先上效果图:

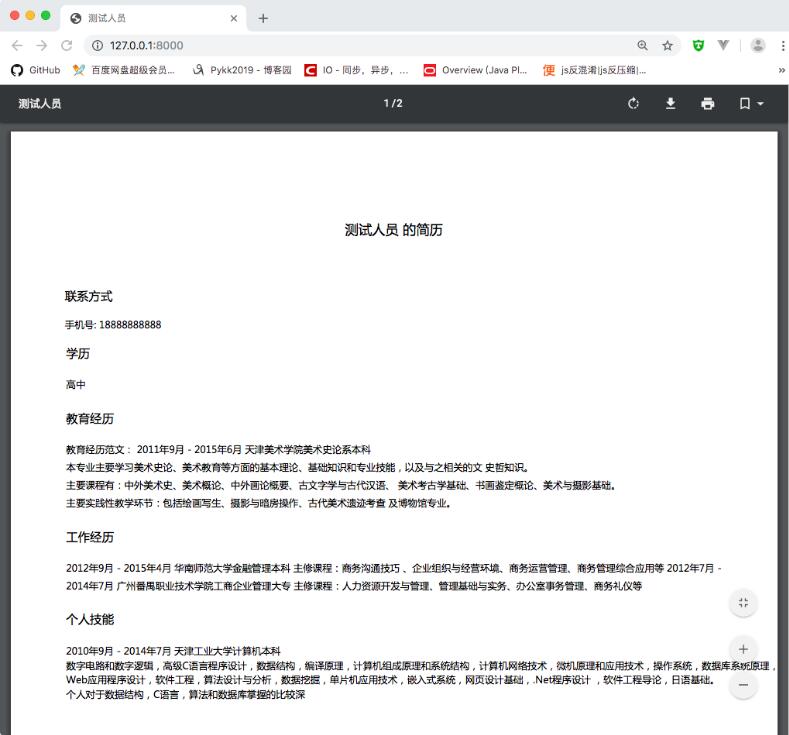
安装依赖库
首先安装Django最新版2.2.2和PDF依赖包xhtml2pdf
pip install django pip install xhtml2pdf
编写表单验证
为了简单起见,这个demo依赖数据库,只需要表单验证数据即可
pdf/forms.py
class MessageForm(forms.Form): ''' 表单验证 ''' name = forms.CharField(required=True) degree = forms.CharField(required=True) edu = forms.CharField(required=True) work = forms.CharField(required=True) tech = forms.CharField(required=True) phone = forms.CharField(required=True)
编写类视图
pdf/views.py
由于这里我们只需要表单视图,所以只创建了一个类视图,post用来验证表单数据是否都存在,如果存在就把表单数据渲染到PDF模板中,经过处理后返回PDF的响应response。
这里可以使用Django的通用类视图FormView构建,代码更简洁
class MessageView(View):
def get(self, request):
form = MessageForm(data=request.GET)
return render(request, 'index.html', {
'form': form
})
def post(self, request):
form = MessageForm(data=request.POST)
if form.is_valid():
response = generate_pdf_response(context=form.cleaned_data)
return response
return redirect(reverse('pdf:message'))
编写生成PDF响应response
view.py这里为了方便直接把处理函数写到视图函数的文件里
def link_callback(uri):
if uri.startswith(settings.MEDIA_URL):
path = os.path.join(settings.MEDIA_ROOT,
uri.replace(settings.MEDIA_URL, ""))
elif uri.startswith(settings.STATIC_URL):
path = os.path.join(settings.STATIC_ROOT,
uri.replace(settings.STATIC_URL, ""))
else:
return uri
# 确保本地文件存在
if not os.path.isfile(path):
raise Exception(
"Media URI 必须以以下格式开头"
f"'{settings.MEDIA_URL}' or '{settings.STATIC_URL}'")
return path
def generate_pdf_response(context):
response = HttpResponse(content_type="application/pdf")
response["Content-Disposition"] = \
f"attachment; filename='{context['name']}.pdf'"
html = render_to_string("pdf.html", context=context)
status = pisa.CreatePDF(html,
dest=response,
link_callback=link_callback)
if status.err:
return HttpResponse("PDF文件生成失败")
return response
解决中文乱码问题
需要下载中文字体msyh.ttf放在static目录下的font目录,用来设置全局字体。这些文件都在github仓库里。
def font_patch():
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.pdfbase import pdfmetrics
from xhtml2pdf.default import DEFAULT_FONT
pdfmetrics.registerFont(TTFont('yh', '{}/font/msyh.ttf'.format(
settings.STATICFILES_DIRS[0])))
DEFAULT_FONT['helvetica'] = 'yh'
把这个函数放在生成PDF响应前
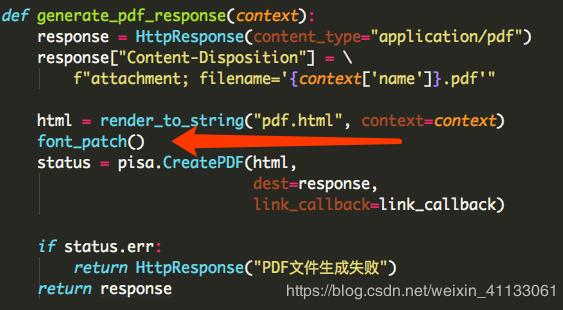
按照以上大致步骤大家就能够生成PDF文件了,可以在网页中浏览、放大、缩小,也可以下载,非常方便、简单。
大家可以直接clone一份代码试试效果
以上这篇Django生成PDF文档显示网页上以及PDF中文显示乱码的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。

